Data Warehouse avec RabbitMQ et Python
Découvrez comment mettre en place un processus ETL avec RabbitMQ et Python pour gérer un Data Warehouse, en utilisant des architectures résilientes et découplées.
4 septembre 2023
Published
Hugo Mufraggi
Author

Data Warehouse Rabbitmq Et Python
Cet article est écrit pour accompagner les étudiants epitech auprès desquels j’interviens.
Le but est de transmettre quelques notions d’architecture et de vous présenter un exemple simpliste d’implémentatoin. Il n’existe pas à ma connaissance, d’architecture type mais plus des paterns d’architecture à assembler avec des choix de technologie pour que ça convienne à vos besoins.
Definition
- ETL (Extract, Transform, Load) : L’ETL est un processus qui extrait des données de diverses sources, les transforment pour les préparer à l’analyse, puis les chargent dans un Data Warehouse. Cela garantit des données de qualité pour les analyses.
- Data Warehouse (Entrepôt de données) : Un Data Warehouse est une base de données centralisée conçue pour stocker et optimiser l’accès aux données. Il facilite les analyses complexes et permet la visualisation des tendances au fil du temps pour prendre des décisions éclairées.
Notion d’architecture
1 — On va chercher à découpler la donnée rentrante et vos données de production.
2- Avoir une architecture résiliante pouvant distribuer les charges.
3 — Faciliter la testabilité du code
4 — Si votre backend est dans le même langage que vos ETL, vous pouvez partager votre domaine entre les deux. https://www.youtube.com/watch?v=_x-z2AwkOFI&t=1s
J’évoquerais ces différents points durant l’artcile.
Cas pratique
Voici notre scénario, on veut synchroniser une source de donnée externe, cleaner notre data et la stocker dans notre db de production. En réalisant l’import en plusieurs étapes, on va pouvoir assurer l’intégrité des données de production. On évite également de casser la prod car le dernier l’api ou le site sur lequel vous scraper à changé des models.
Pour l’exemple, nous réaliserons un ETL import de pokemon ( ce n’est pas très original mais c’est gratuit).
Choix technique
Base de donnée data warehouse: J’ai choisi une base de données mongo (no sql) pour pouvoir stocker les objects que j’ai récupéré en l’état.
Base de données production: Pour l’article, j’ai réutiliser une base de données mongo pour une question de rapidité d’écriture de l’article. Je vous invite à essayer avec une db posgresl (sql).
Message broker: J’ai choisi d’utiliser Rabbitnq. Il existe d’autres alternatives qui ont chacun leur propre manière de fonctionner. (Kafka, aws SQS, pub sub, ect..)
Vue d’ensemble
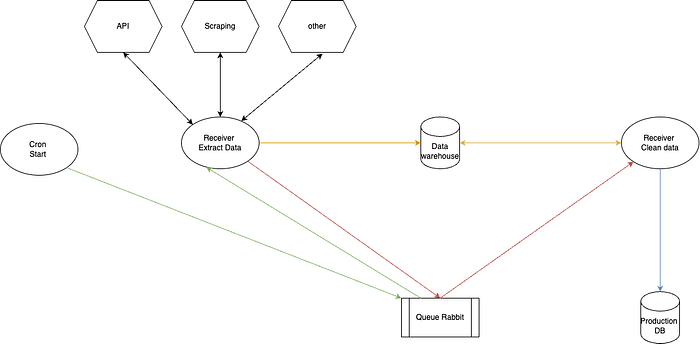
Notre ETL sera constitué de:
- Il sera composé d’un script de lancement. Dans notre cas, ce sera un script mais ça pourrait être un cron. Ce script parcourera cette liste et publira chaque id dans un message dans le rabbitnq. Ce sont les flèches en vert.
- Le receiver Extract object va dépiler les messages et va faire appel à l’api de pokemon et stocker le résultat dans notre data warehouse. Une fois stocké, on publiera un nouveau dans une nouvelle queue avec id mongo. Ce sont les flèches orange et rouge.
- Le receiver clean data va quant à lui recevoir un id mongo load object et stocker une version cleaner dans la db de production.
Infrastructure
On va lancer en local 2 mongo et un contener pour le rabbit and queue. Pour cela, vous allez avoir besoin de docker.
docker run -d -p 27017:27017 --name mongodb1 mongo
docker run -d -p 27018:27017 --name mongodb2 mongo
La mongodb1 sera notre db pour la data warehouse et la mongodb2 celle pour la prod.
La mongodb1 ecoutera sur le port 27017 et la mongodb2 27018 .
Pour rabbit vous trouverez ici un tutorial complet.
docker run --rm -it --hostname my-rabbit -p 15672:15672 -p 5672:5672 rabbitmq:3-management
Le port 15672 est celui de l’interface utilisateur et 5672 celui où l’on publie les messages.
Les identifiants pour se connecter sur l’interface utilisateur sont guest:guest.
Une fois connecté, aller sur cet url http://localhost:15672/#/queues . Ca sera là que toutes les queues seront listées.
Le code
Nous allons découper notre code de la manière suivante. Le but est d’avoir de petits class python faciles à tester et peu couplés.
- Deux repository pour écrire dans le data warehouse et dans la db de prod.
- Un client http pour consomer l’api pokemon.
- un domain pour centraliser les définitions de class et les interfaces.
- Et les reciever.
Ce qui donne une architecture de repo suivante:
src
├── api
│ └── pokemon_api_client.py
├── domain
│ └── pokemon_raw.py
├── receivers
│ ├── pokemon_api_receivers.py
│ └── pokemon_sync_production.py
└── repository
├── pokemon_production_repository.py
└── pokemon_row_repository.py
Dans la suite de l’article, je ne couvrirais pas la partie domain mais un seul receiver et repository.
Pour éviter la redondance, tout le code est disponible sur mon github.
API
Pour notre cas, j’ai choisi de juste faire une fonction qui sera importée dans le reciever. Si vous avez plusieurs endpoint sur la même api, faites une class client dedier.
def fetch_pokemon_data(url, pokemon_id):
try:
response = requests.get(url + str(pokemon_id))
if response.status_code == 200:
pokemon_data = response.json()
pokemon = PokemonModel(**pokemon_data)
return pokemon
else:
print(f"The request failed with status code {response.status_code}")
return None
except requests.exceptions.RequestException as e:
print(f"An error occurred during the request: {e}")
return None
except ValidationError as e:
print(f"An error occurred during the request: {e}")
return None
J’utilise Pydantic pour pouvoir typer la réponse de api et m’assurer qu’il n’y a pas eu de changement. Si oui ça retournera une erreur.
Repository
class PokemonRawRepository:
def __init__(self, db_url, db_name, collection_name):
self.client = MongoClient(db_url)
self.db = self.client[db_name]
self.collection = self.db[collection_name]
def insert(self, data):
return self.collection.insert_one(data)
def find_one_by_id(self, id):
return self.collection.find_one({"_id": id})
def get_pokemon_row_repository():
db_url = "mongodb://localhost:27017/"
db_name = "data_warehouse"
collection_name = "pokemon"
return PokemonRawRepository(db_url, db_name, collection_name)
PS: En général, je récuperais db_url, db_name et collection_name depuis des variables d’env.
Receivers
Votre fonction va devoir respecter une certaine définition qui est imposée par pika. Elle sera utilisée comme call back par pika quand un message arrivera.
repository = get_pokemon_row_repository()
queue_api_sync = 'pokemon_sync_api'
def callback_pokemon_api_call(ch, method, properties, body):
message_body = body.decode('utf-8')
message_data = json.loads(message_body)
id_value = message_data.get('id')
pokemon = fetch_pokemon_data("https://api-pokemon-fr.vercel.app/api/v1/pokemon/", id_value)
created = repository.insert(pokemon.dict())
message = json.dumps({"id": str(created.inserted_id)})
ch.basic_publish(exchange='', routing_key=queue_sync_production, body=message)
Premièrement, nous allons récupérer le body, le decoder et en faire un object json. Attention il va falloir tenir à jour de la documentation pour fixer les contracts de vos différentes queue rabbit.
Le body a besoin d’être toujours le même pour pas que le code plante.
Dans notre cas, nous avons un object définit comme ca:
{id: 12 }
Apres avoir récupéré l’id, je fais appel à mon api avec fetch_pokemon_data. Puis j’insers dans ma data ware house l’object tel quel avec repository.insert(pokemon.dict()) .
Il ne reste plus qu’à préparer le message pour la prochaine queue, celle qui aura pour tâche de clean l’object et de l’insérer dans la db de production. La variable routing_key=queue_sync_production contient le nom de la queue où on va envoyer le message. queue_sync_production est définie dans pokemon_sync_production.py.
Main
Dans le Main nous allons:
- Faire l’init de notre channel pika.
- Déclarer nos queue. Pika s’occupera de les créé dans le rabbitnq.
- Et ajouter des consumer
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost', port=5672))
channel = connection.channel()
channel.queue_declare(queue=queue_api_sync)
channel.queue_declare(queue=queue_sync_production)
channel.basic_consume(queue=queue_api_sync, on_message_callback=callback_pokemon_api_call, auto_ack=True)
channel.basic_consume(queue=queue_sync_production, on_message_callback=callback_pokemon_sync_production, auto_ack=True)
PS: Tout ce qui est lié est mis dans un fichier à part et une classe distincte. On a juste besoin d’avoir une fonction qui nous retourne le channel.
Ensuite on veut push des messages dans la queue queue_api_sync Pour cela, on va faire une boucle for de 0 a 1011, cela nous permettra de générer tous les id des pokemon.
for id in range(1011):
message = json.dumps({"id": str(id)})
channel.basic_publish(exchange='', routing_key=queue_api_sync, body=message) channel.start_consuming()
Puis nous lancons le channel. Les messages vont s’envoyer et vont être traité de manière asynchrone.
Conclusion
J’espère que cette initiation au système distribuer, vous aura transmis quelques notions d’architecture. Et vous aidera face à vos prochains challenges techniques.